| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Multivariate Daten Modellbildung Klassifizierung und Diskriminierung KNN Klassifikation Multivariate Daten Modellbildung Klassifizierung und Diskriminierung KNN Klassifikation |
|
| Siehe auch: Klassifikation vs. Kalibration, Diskrimination und Klassifikation | |
| Search the VIAS Library | Index |   |
|
KNN-KlassifikationAuthor: Hans Lohninger
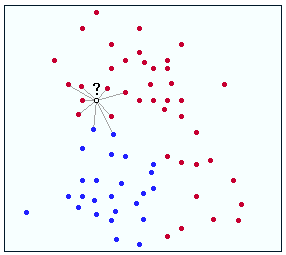
K-Nearest Neighbor (KNN)-Klassifikation ist eine einfache, aber dennoch sehr effiziente Klassifikationsmethode. Der entscheidende Gedanke hinter der KNN-Klassifikation ist, dass einander ähnliche Messwerte zu gleichen Klassen gehören. Somit muss man nur die Klassenbezeichner einer gewissen Zahl der nächsten Nachbarn kennen, um die Klassennummer eines unbekannten Messwertes schätzen zu können.
Die Ermittlung der Klassennummer eines unbekannten Objekts erfolgt oft durch das Mehrheitskriterium, aber auch andere Schemata sind denkbar. Die Zahl der nächsten Nachbarn k sollte ungerade sein, um Gleichstände zu vermeiden, und sie sollte möglichst klein gehalten werden, da ein großes k zu einer schlechten Klassifikation führen kann, wenn die einzelnen Klassen nicht gut getrennt sind. Die Güte eines KNN-Klassifikators entspricht zumindest immer der Hälfte des bestmöglichen Klassifikators für ein gegebenes Problem. Einer der größten Nachteile von KNN-Klassifikatoren ist, dass der Klassifikator immer alle verfügbaren Daten benötigt, was zu beträchtlichem Aufwand führen kann, wenn die Trainingsdatenmenge sehr groß ist.
|
|
| Home Multivariate Daten Modellbildung Klassifizierung und Diskriminierung KNN Klassifikation |
|
Last Update: 2021-08-15