| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Grundlagen Indikatorvariable Grundlagen Indikatorvariable |
|||||
| Siehe auch: Dichotome Merkmale | |||||
| Search the VIAS Library | Index |   |
||||
|
IndikatorvariableAuthor: Hans Lohninger
Unter einer Indikatorvariable versteht man eine binäre Variable, die durch die Werte 0 und 1 (oder -1 und +1) anzeigt, ob das jeweilige Objekt eine bestimmte Eigenschaft aufweist oder nicht. Indikatorvariablen können sowohl direkt erhoben werden (z.B. das Geschlecht einer Versuchsperson) als auch aus anderen Variablen errechnet bzw. erzeugt werden. Für den zweiten Fall gibt es im Wesentlichen zwei Szenarien, die in der Praxis wichtig sind: Dichotomisierung einer kontinuierlichen Variablen: Bei manchen Untersuchungen wird zwar ein kontinuierlicher Wert erhoben, für die spätere Analyse ist aber nur entscheidend, ob diese Variable einen bestimmten Wert überschreitet oder unterschreitet. Man interessiert sich also nur für zwei Zustände (Überschreitung der Grenze, ja oder nein). Die daraus resultierende Variable nennt man eine dichotome oder binäre Variable. Die Grenze für die Dichotomisierung wird klarerweise durch die jeweilige Fragestellung vorgegeben. Es ist also denkbar, dass man aus einer kontinuierlichen Variable mehr als eine Indikatorvariable ableitet.
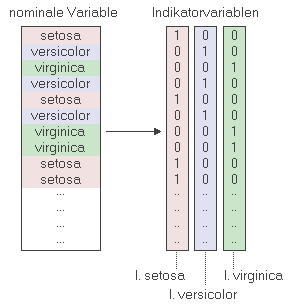
Aufspaltung von nominalen bzw. ordinalen Variablen: Enthält eine Variable die Beschreibung mehrerer Zustände, in dem jedem Zustand z.B. eine Nummer zugeordnet wird, so ist diese Variable zum direkten Einsatz in statistischen Modellen mehr oder minder unbrauchbar, da im Fall einer nominal skalierten Variable diese nicht direkt in einem Modell eingesetzt werden kann und selbst bei ordinal skalierten Variablen der Einsatz in statistischen Modellen stark eingeschränkt sein kann. Man hilft sich in solchen Fällen, in dem man die verschiedenen Zustände einer solchen Variablen in eine entsprechende Zahl an Indikatorvariablen aufspaltet. Dabei enthält jede Indikatorvariable jeweils 1 oder 0, je nach dem, ob der jeweilige Zustand auftritt oder nicht.
|
|||||
| Home Grundlagen Indikatorvariable |
|
||||


Last Update: 2012-10-18